
In this guide, we’ll use the web interface as a basis. But the concepts and queries are the same for the CLI versions of JODA.
Basic JODA Concepts
JODA is a data processing framework that filters, transforms, and aggregates JSON datasets. These datasets are named collections in JODA and are the basic building blocks of your data pipeline. They are comparable to SQL tables or MongoDB collections.
Every collection is split into multiple internal containers, consisting of a subset of the JSON documents included in the collection. Containers are independent of each other, allowing the execution of a query on multiple CPU threads without any locking.
Each query in JODA has the same basic structure:
LOAD <COLLECTION> (<SOURCES>)
(CHOOSE <PRED>)
(AS <PROJ>)
(AGG <AGG>)
(STORE <COLLECTION> | AS FILE "<FILE>" | AS FILES "<DIR>")
(DELETE <COLLECTION>)
The LOAD command loads a collection from the internal memory or imports additional datasets from a supported source.
CHOOSE filters the collection with a predicate, which is evaluated for every document in the collection.
AS projects each document in the collection according to the given instructions.
AGG then aggregates all documents into a single aggregation result.
With STORE the resulting collection can either be stored in another internal collection for later use or exported into multiple files.
Finally, DELETE removes a collection from the internal memory.
The complete language reference is available here:
Collection documents cannot be viewed directly and must be queried first. Results are created by every query execution and can be used to repeatedly view or download the resulting dataset until they are removed.
Web Interface Layout
The starting page of the web interface contains the essential information of the current data.
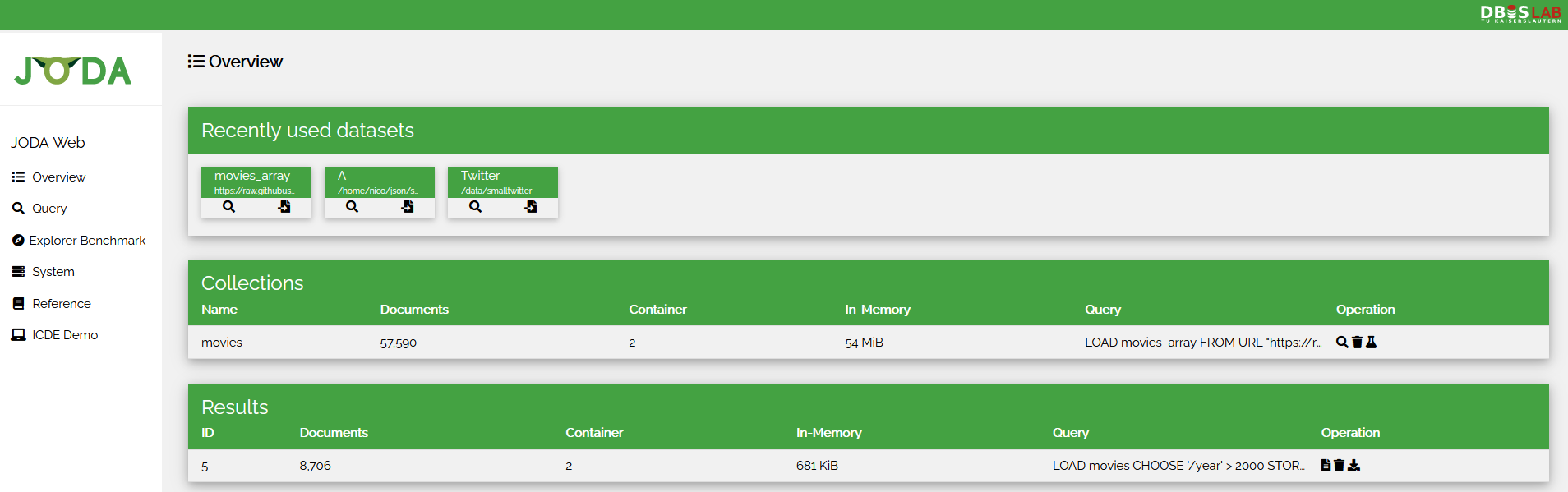
If you imported datasets during previous runs of JODA, they are shown at the top of the page with buttons to import them again or change the responsible queries immediately.
Below a list of all currently imported collections is shown. The name, number of included documents, size, and query that created the collection are shown for each collection. For every collection, we can create a query referencing the collection, delete the collection, or analyze it using the buttons on the right.
Similarly, the list of all available results is shown below. Results are not named but are assigned a unique ID with which they can be referenced. To the right, the result documents can be viewed, removed, or downloaded in line-separated JSON format.
At the sidebar to the left, the different functions can be accessed.
- overview brings you to the currently introduced starting page.
- query lets you execute new queries to the system.
- system shows an overview of the JODA and OS versions, together with the current memory usage of the host machine and the JODA system itself.
Query & Result
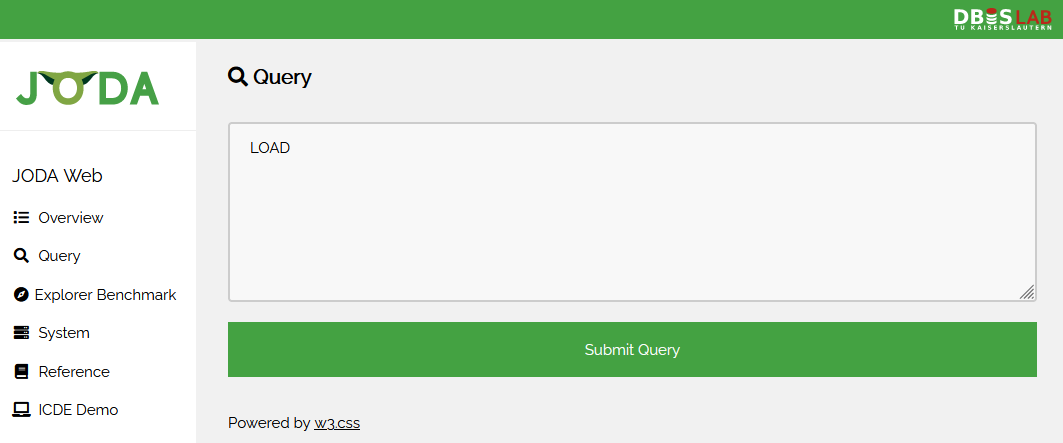
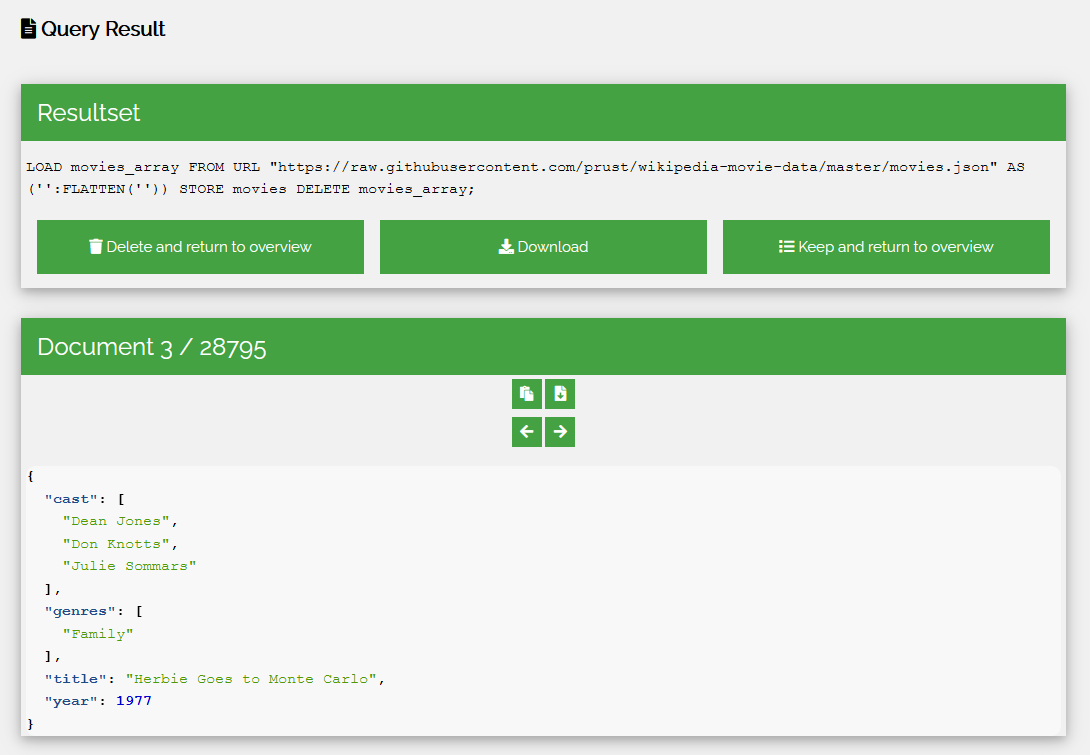
The query interface consists of a simple textbox and a button to execute the query. If the query is successful, we are shown the query result screen in which we can see the result size and basic execution statistics.

From here, the result documents can either be downloaded, or viewed. When choosing to view the documents, each document can be browsed by using the buttons or left and right arrow keys. Every document can also be copied to the clipboard, or downloaded. At the top, we can choose to download the result set, or to delete or keep it and return to the overview. If a document is in GeoJSON format, a map can be displayed to visualize the contents.
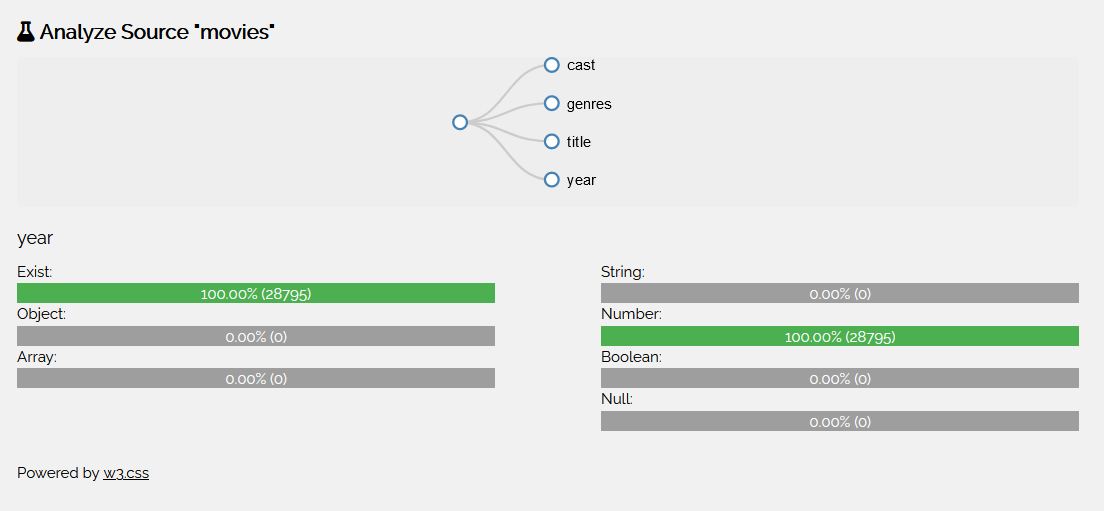
Analyze
The web interface can also show a summary over the structure of a collection, using the analyze operation in the overview. Here the attributes of all documents in the collection are summarized and displayed in a graph. When hovering over a node, statistics about the type-distribution and existence of the attribute is shown.
Query Examples
Now that we know the basics, we can start with some examples. We will start with obtaining a publicly available dataset of movies. The JSON file looks like this:
[{"title":"After Dark in Central Park","year":1900,"cast":[],"genres":[]}, ...]
To fetch this dataset we use:
LOAD temp FROM URL "https://raw.githubusercontent.com/prust/wikipedia-movie-data/master/movies.json"
AS ('':FLATTEN(''))
STORE movies
DELETE temp;
The first command loads the dataset from the URL and stores it in the internal collection temp.
As the dataset consists of only one large JSON array containing all movies, we flatten it using the FLATTEN function to split this array into individual documents.
We store this dataset in the movies collection.
Finally, we delete the temporary collection.
The resulting documents look like:
{"cast":["Linda Blair","Richard Burton"],"genres":["Horror"],"title":"Exorcist II: The Heretic","year":1977}
Now that we can access each movie independently, we can query for all action movies.
LOAD movies
CHOOSE IN("Action", '/genres')
STORE action_movies;
For this, we filter the dataset using the CHOOSE command.
As genres are an array of strings, we will use the IN(<element>, <array>) function to check if the movie genre list contains “Action”.
The structure of the documents will be the same, except that only action movies remain.
Using the set of action movies, we will now create a list of actors, together with the movie they played in.
LOAD action_movies
AS ('/actor': FLATTEN('/cast')), ('/movie': '/title'), ('/year': '/year')
STORE action_actors
Once again, we use the FLATTEN function to create one document per actor in the cast array. But now, we additionally also add the movie title and the year of release. This will give us the following JSON documents:
{"actor":"Janet Gaynor","movie":"Tess of the Storm Country","year":1932}
Using this list, we will now list all actors together with every movie. We will need multiple queries to achieve this.
LOAD action_actors
AGG ('' : GROUP DISTINCT('/movie') AS movies BY '/actor')
STORE groupedActors;
LOAD groupedActors
AS ('':FLATTEN(''))
STORE flattenedActors
DELETE groupedActors;
LOAD flattenedActors
AS ('/actor' : '/group') ,('/movies':'/movies')
DELETE flattenedActors
STORE AS FILE "action-actors.json"
The first query aggregates all documents by grouping them by the actor and collecting a distinct list of movie titles. The intermediate result will have the following format:
[
{"group": "Janet Gaynor", "movies": ["Tess of the Storm Country", ...] }
...
]
This result is then flattened again into separate documents per actor with the second query.
Finally, we rename the group attribute to actor and keep the movies attribute to obtain our final documents containing action-movie actors together with a list of their movie titles.
The result is stored as a line-separated JSON file in action-actors.json.